
「自社の資料に基づいて質問に答えるAIを作りたい」
「プログラミングなしで高性能なチャットボットを作れないだろうか」
とお考えではありませんか?
この記事では、Difyというノーコードツールを使って、RAG(検索拡張生成)システムを構築する方法を詳しく解説します。
専門知識がなくても、自社の資料や専門文書に基づいて回答するAIチャットボットを作れるようになります!

生成AI活用の教科書
生成AIの専門家として、1000人以上が参加するAIセミナーを100回以上開催した実績を持つ。国会議事堂衆議院会館や三井物産株式会社などの一流機関でのAIセミナー主催、生成AIタスクフォースへの参画、Shift AIでの講師活動など幅広く活躍。5000名を超える「人生逃げ切りサロン」のAI講座監修や、上場企業におけるAI顧問・システム開発・研修なども手がける。総フォロワー数32万人を誇るAI情報発信アカウントを運営し、過去には3つの事業のM&A経験を持つなど、AIと経営の両面で豊富な知識と経験を有している。

RAGの仕組みとDifyでの実践的活用法

AIチャットボットを作る際に重要なのが、正確な情報をもとに回答させるという点です。
この記事では、まずRAGの基本概念と仕組みをわかりやすく解説し、次に実際にDifyでの実装方法を見ていきます。
技術的な内容も含まれますが、初心者の方にもイメージしやすいよう、身近な例えを交えながら説明していきますので、安心して読み進めてください。
RAGとは?わかりやすく解説
RAG(Retrieval-Augmented Generation)とは「検索拡張生成」と訳され、AIが回答を生成する前に関連情報を検索・参照する仕組みです。
例えるなら、記憶だけで答えるのではなく、手元の資料を見ながら回答するイメージです。
通常のAI(LLM)は、学習済みの知識の範囲でしか答えられず、最新情報や専門的な内容に弱い面があります。
一方、RAGシステムでは、質問に関連する情報を自分で用意した資料から検索し、その情報を基に回答を生成します。
RAGの流れは次のようになります。
- ユーザーが質問する
- システムが関連資料を検索
- 検索結果をもとに回答を生成
この仕組みにより、AIが「知らない」「古い」「間違った」情報で回答することを防ぎ、より正確で信頼性の高い応答が可能になります。
社内マニュアルや製品資料など、特定の知識ベースに基づいた質問応答システムを構築するのに最適な技術です。
RAG実装の基本
RAGシステムの実装には、一般的に以下の要素が必要です。
- データ処理
PDFや文書ファイルを読み込み、小さな「チャンク」と呼ばれる断片に分割します。これは大きな文書を扱いやすいサイズに切り分ける作業です。 - ベクトル化
各チャンクをAIが理解できる数値データ(ベクトル)に変換します。これにより、意味的に似た内容を検索できるようになります。 - 検索
質問が入力されると、質問もベクトル化され、最も関連性の高いチャンクを見つけ出します。これは似た意味の内容を探す作業です。 - 生成
検索で見つかった関連情報をAIモデルに与え、最終的な回答を生成します。
これらの手順は通常、複雑なプログラミングが必要ですが、Difyを使えば、専門知識がなくても直感的な操作で実装できます。
Difyは上記のすべてのプロセスを自動化し、視覚的なインターフェースで管理できるため、初心者でも短時間でRAGシステムを構築できるのです。
実際にDifyでRAGアプリを作成する手順
さあ、ここからは実際にDifyを使ってRAGチャットボットを作成する手順を、ステップバイステップで解説していきます。
初めての方でも迷わず進められるよう丁寧に説明しますので、各ステップを順番に進めるだけで、あなただけの知識ベース連携AIチャットボットが完成します。
それでは、さっそく始めましょう!
STEP①Difyのセットアップ
※すでにDifyアカウントをお持ちの方や環境構築がお済みの方は、このステップを飛ばして次に進んでください。
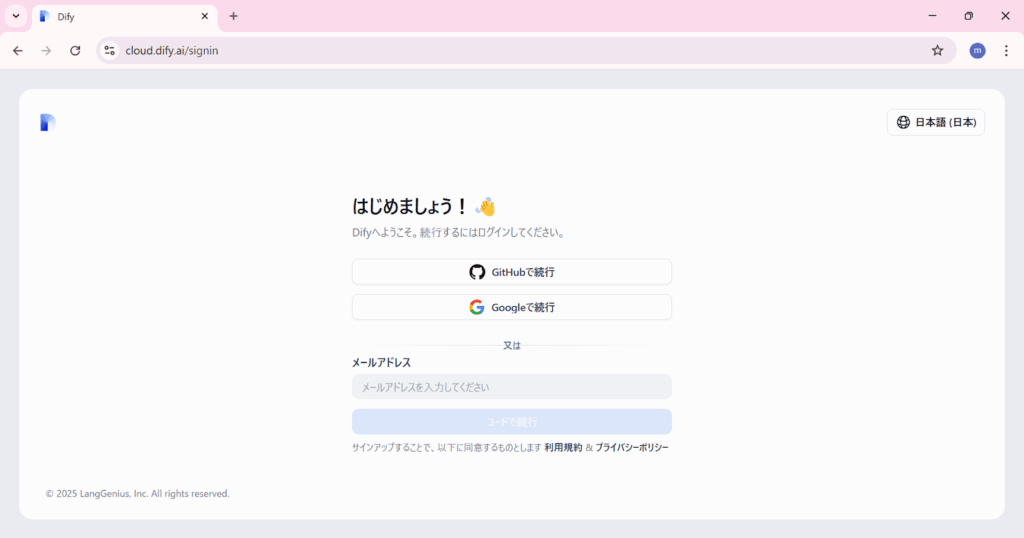
Difyを利用するには、クラウド版かセルフホスト版のいずれかを選択する必要があります。
初心者の方には、すぐに利用開始できるクラウド版がおすすめです。
セルフホスト版はご自身のサーバーにDifyをインストールして利用する方法です。Docker環境が必要となりますが、データをすべて自社内で管理できるメリットがあります。詳細なインストール方法は割愛させていただきますが、気になる方は別の記事や公式ドキュメントなどを参照してください。
STEP②「チャットボット」> 「最初から作成」
アカウント作成後、実際にRAGチャットボットを作成していきましょう。
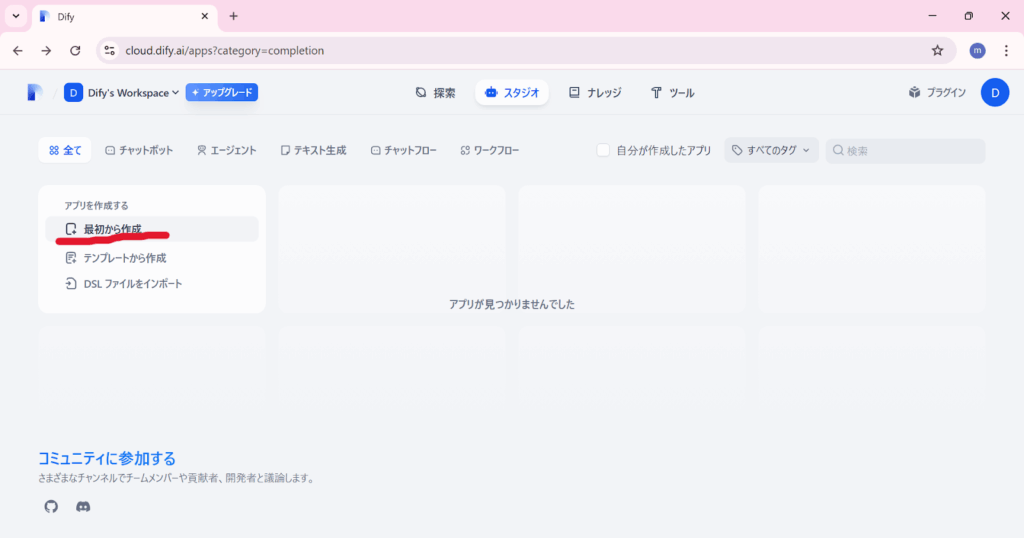
- アプリ名:わかりやすい名前をつけましょう(例:「社内FAQボット」)
- 説明:どんな目的のボットか簡単に記述します
- アイコン:必要に応じて設定します
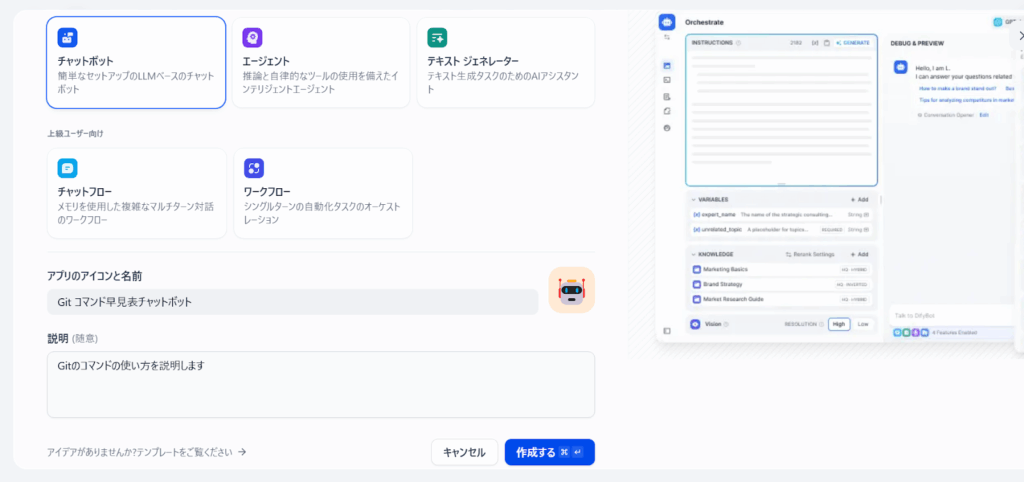
これでチャットボットの基本設定が完了しました。
次にプロンプト画面が表示されますが、RAGを設定する前にまずはナレッジベースを準備していきましょう。
プロンプトの部分は後ほど設定します。
STEP③「オーケストレーション」>「ナレッジ」>「追加」
RAGシステムの核となるナレッジベースを設定していきます。
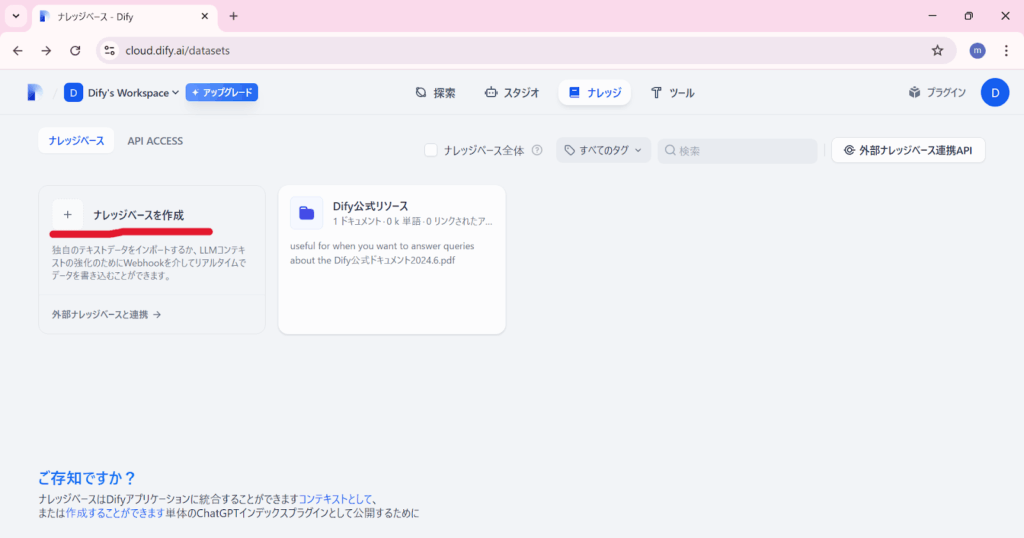
「テキストファイルからインポート」をクリックし、ファイルをドラッグ&ドロップするか「参照」からファイルを選択します。
Difyは様々な形式のドキュメントに対応しているため、用途に合わせて最適なフォーマットを選びましょう。
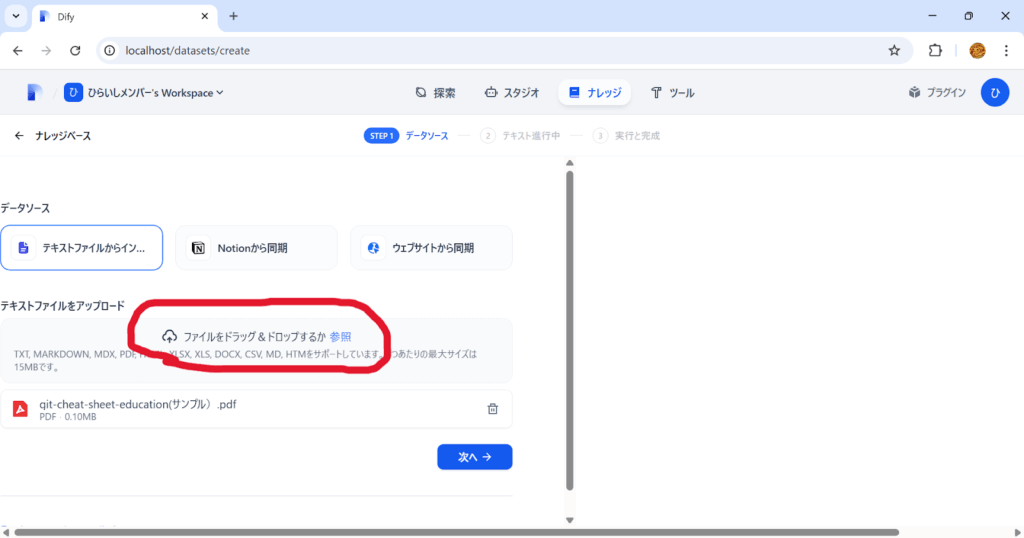
STEP④ナレッジ・ドキュメントを準備
RAGシステムの精度は、入力するドキュメントの質に大きく左右されます。
効果的なナレッジベースを構築するためのポイントを紹介します。
- PDF:最も一般的に使用されるフォーマットです
- DOCX:Wordドキュメント
- TXT:プレーンテキスト
- Markdown:構造化された文書に適しています
- ファイルサイズに注意
大きすぎるファイルは処理に時間がかかります。また、Difyクラウド版の無料プランでは単一ファイルで15MB、トータルで50MBまでの容量制限があります。 - テキスト認識可能なPDFを使用
スキャンしただけのPDFは文字認識ができない場合があります。テキスト抽出可能なPDFを使用しましょう。 - 構造化された文書が理想的
見出しや章立てが明確な文書の方が、AIが内容を理解しやすくなります。 - 関連性の高い情報を集約
質問される可能性が高いトピックに関する情報を網羅することで、回答の質が向上します。
準備したドキュメントをナレッジベースにアップロードし、処理が完了するのを待ちます。
アップロード後、Difyがドキュメントを自動的に処理し、検索可能な形式に変換します。
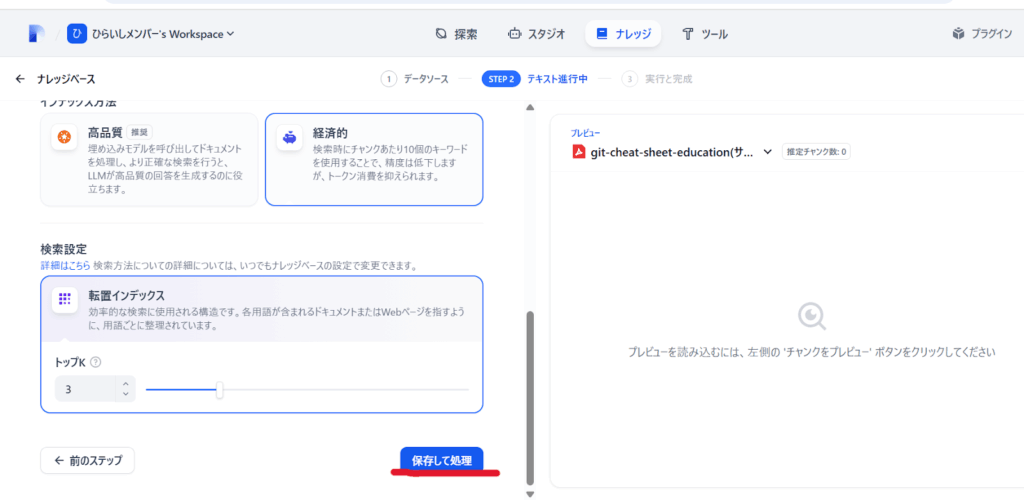
STEP⑤参照する知識を選択
ナレッジベースにドキュメントをアップロードした後は、それをチャットボットに連携させる必要があります。
以下の手順で設定します。
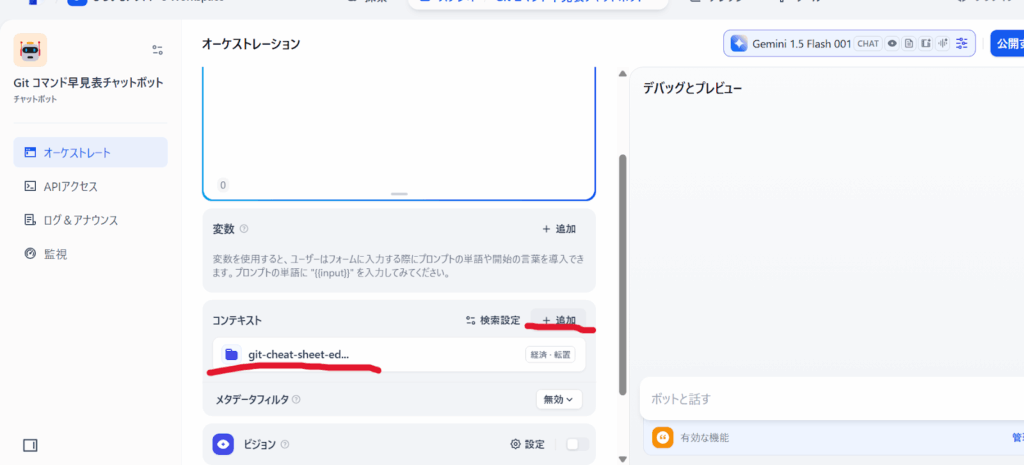
選択したナレッジベースが追加されたことを確認してください。
これでチャットボットとナレッジベースが連携され、RAGの基本的な機能が有効になりました。
連携されたナレッジベースは、質問に応じて自動的に参照されるようになります。
必要に応じて複数のナレッジベースを連携することも可能です。
この設定により、ユーザーからの質問があった時に、まずナレッジベース内の関連情報を検索し、その結果を基にAIが回答を生成するという流れが完成します。
STEP⑥プロンプトの設定
RAGシステムの性能を最大限に引き出すためには、適切なプロンプト設定が重要です。
プロンプトとは、AIに対する指示書のようなものであり、どのように回答を生成すべきかを定義します。
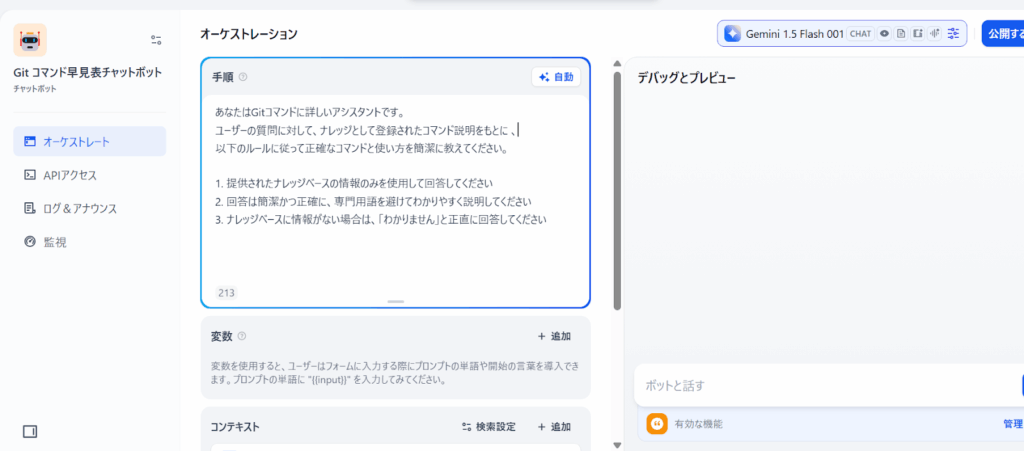
あなたは{会社名}の製品に関する専門家アシスタントです。ユーザーの質問に対して、以下のルールに従って回答してください。
1. 提供されたナレッジベースの情報のみを使用して回答してください
2. 回答は簡潔かつ正確に、専門用語を避けてわかりやすく説明してください
3. 製品の特徴や使い方について質問された場合は、具体的な手順や例を含めて説明してください
4. ナレッジベースに情報がない場合は、カスタマーサービスへの問い合わせを誘導してください
このようなプロンプトを設定することで、AIはナレッジベースの情報に基づいた適切な回答を生成するよう指示されます。
必要に応じてプロンプトを調整し、回答の調子やスタイルをカスタマイズすることも可能です。
STEP⑦テストと最適化
RAGシステムを構築したら、実際に動作テストを行い、必要に応じて最適化しましょう。
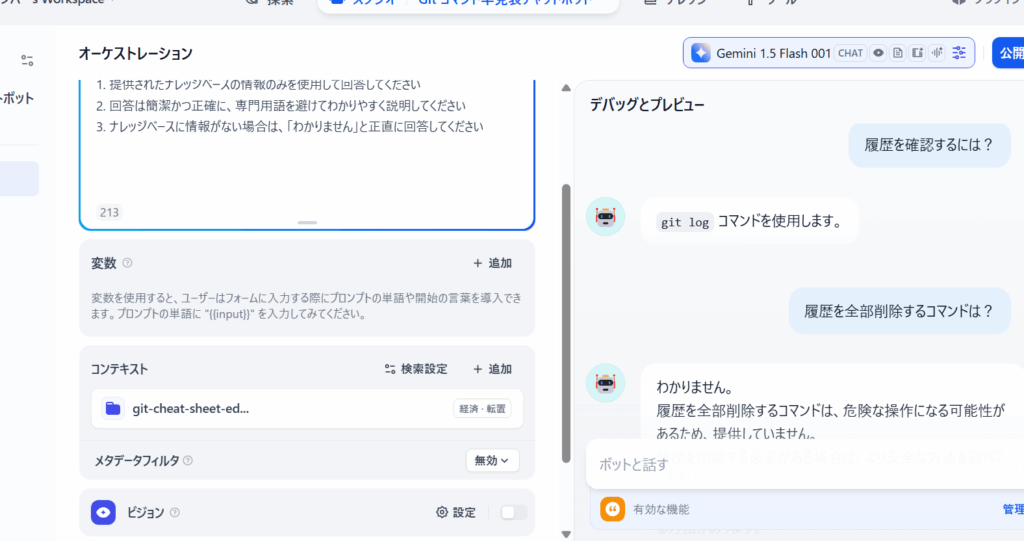
- 質問に対して関連性の高い情報を取得できているか
- 回答が正確で、ナレッジベースの情報に基づいているか
- 情報がない場合は正直に「わからない」と回答しているか(勝手な回答をしていないか)
テストを繰り返しながら調整することで、徐々に回答の精度が向上していきます。
精度を向上させるコツについては後ほど解説します。
STEP⑧APIとデプロイ
RAGチャットボットの動作に問題がなければ、いよいよ公開・デプロイのステップです。
Difyでは複数の方法でチャットボットを公開・利用できます。
1. ウェブページとして公開
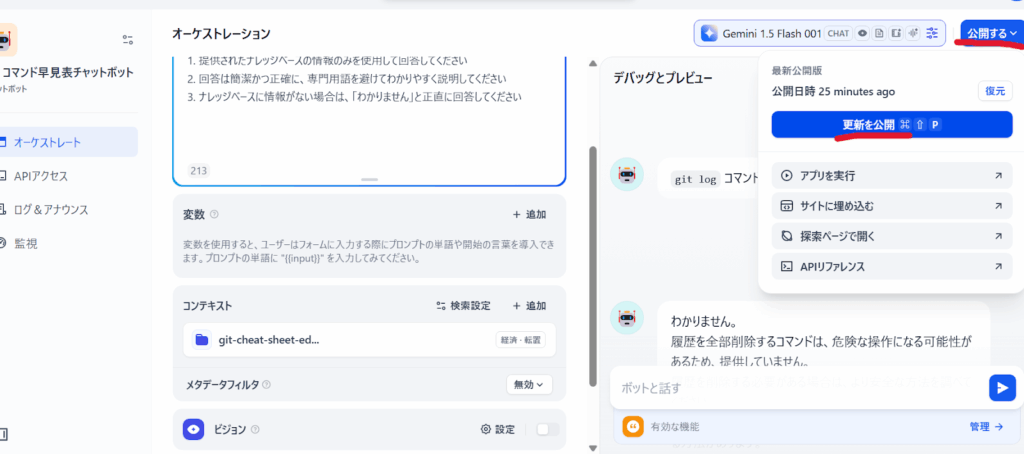
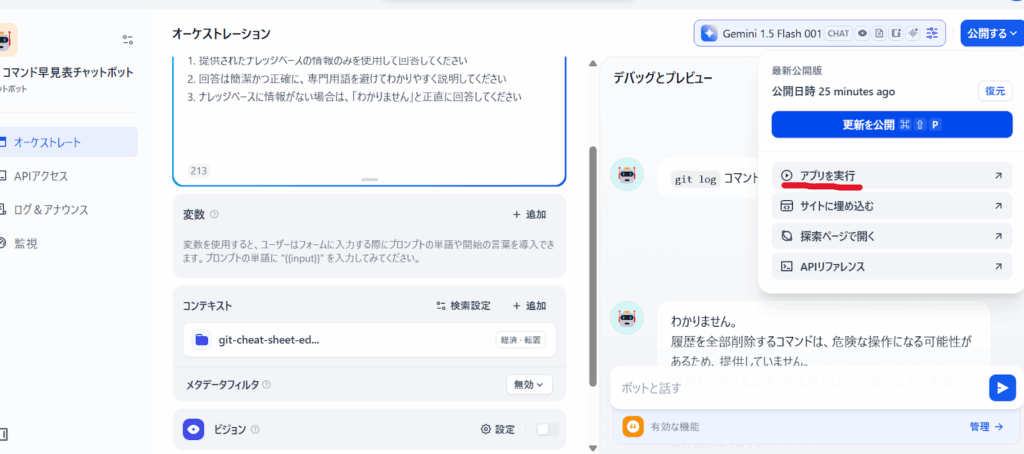
2. API経由で利用

3. サイトに埋め込む

- APIキーは機密情報なので、安全に管理してください
- アクセス制限を設定する場合は、公開設定で「アクセス制御」を有効にします
- 利用量の多いサービスでは、有料プランへのアップグレードを検討しましょう
これでRAGチャットボットの基本的な構築と公開のプロセスは完了です。
次のセクションでは、さらに精度を向上させるための方法を解説します。
DifyでRAGの精度を向上させるための方法

基本的なRAGチャットボットの構築方法を学んだところで、次はさらに精度を高めるためのテクニックを見ていきましょう。
ここからは少し踏み込んだ内容になりますが、これらの最適化を行うことで、チャットボットの回答品質が大きく向上します。
実際のプロジェクトで差をつけるノウハウを紹介していきますので、ぜひ挑戦してみてください。
データ処理を最適化させる
RAGシステムの品質向上の第一歩は、データ処理の最適化です。
Difyでは以下のようなデータ処理の調整が可能です。
チャンクサイズの最適化
チャンクサイズは、文書を分割する単位の大きさを指します。Difyのナレッジベース設定画面で調整可能です。

- 小さすぎるチャンクサイズ(200字程度):文脈が失われ、回答が断片的になりがち
- 大きすぎるチャンクサイズ(2000字以上):無関係な情報も含まれ、回答の精度が下がる
- 推奨サイズ:日本語文書の場合、500〜1000字程度が効果的と言われている
チャンクオーバーラップの設定
各チャンク間に重複部分を設けることで、文脈の連続性を保持できます。
Difyではオーバーラップ率として設定可能で、10〜20%程度の重複が一般的です。
メタデータの活用
ドキュメントにタグやカテゴリなどのメタデータを追加することで、検索精度が向上します。
ドキュメントごとにメタデータを設定でき、例えば「製品カテゴリ」「更新日」などの情報を付加しておくと、より関連性の高い情報検索が可能になります。
インデックス・検索を改善する
RAGシステムの心臓部とも言えるのが検索機能です。
Difyでは以下の方法で検索精度を向上させることができます。
ベクトルストアの選択
Difyは複数のベクトルデータベース(ベクトルストア)に対応しています。
デフォルトの組み込みベクトルストアでも十分ですが、より高度な検索が必要な場合は、Milvus、Qdrantのような外部ベクトルストアの連携も検討しましょう。
これらはDify設定画面の「設定」→「ベクトルデータベース」から設定できます。
※バージョンやプランによっては選択不可
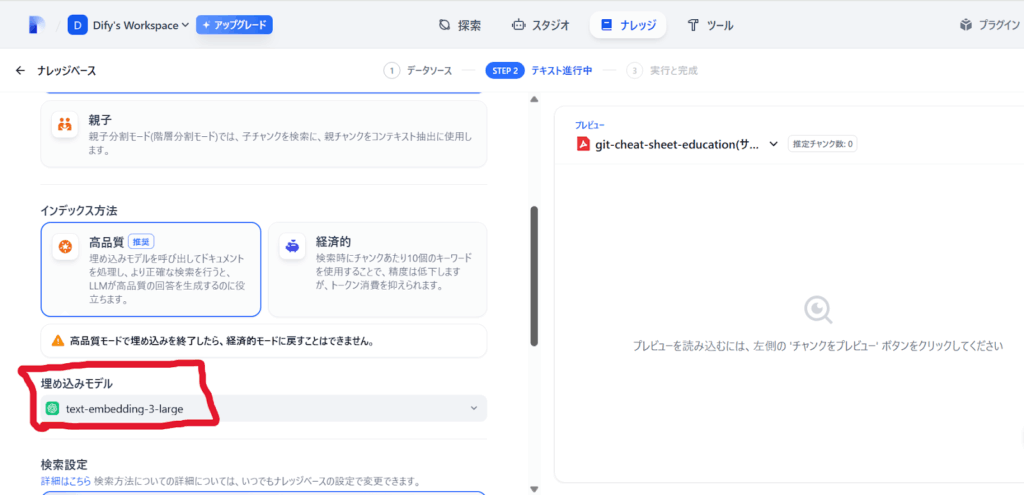
埋め込みモデルの選択
テキストをベクトル化する際に使用される「埋め込みモデル」の選択も重要です。
Difyでは複数の埋め込みモデルに対応しており、モデルプロバイダーの設定画面から選択できます。
日本語文書を扱う場合は、多言語対応の埋め込みモデル(OpenAIのtext-embedding-3など)が効果的です。
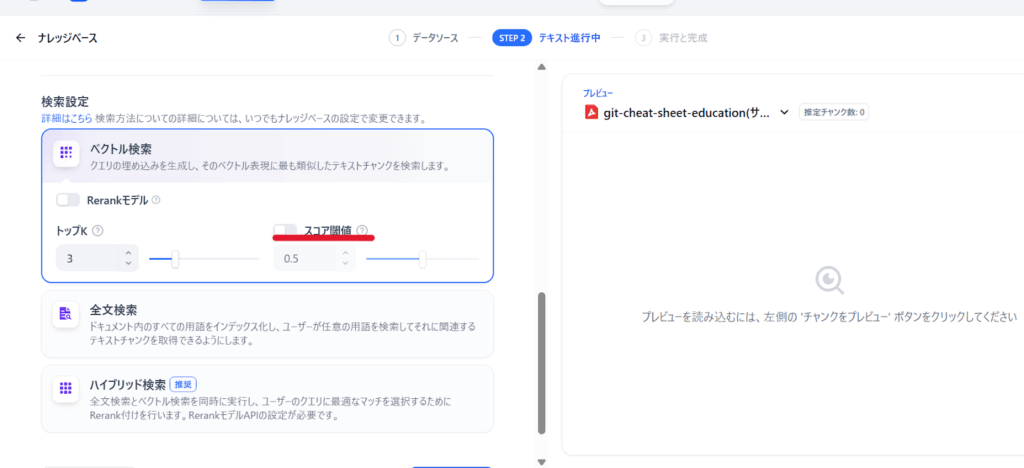
類似度スコアの調整
検索結果の関連性を判断する「類似度スコア」の閾値を調整することで、回答の質を向上させられます。
Difyのナレッジベース設定で「最小類似度スコア」を指定できます。
値を上げると厳密な検索になりますが、該当情報が見つからないケースも増えます。
まずは0.7程度から始めて調整するとよいでしょう。
プロンプトエンジニアリングを行う
RAGシステムの出力品質を大きく左右するのがプロンプトの設計です。
より詳細なシステムプロンプトを設定することで回答の質が向上します。
ここではプロンプトの改善をビフォー&アフターで見ていきましょう。
あなたは{会社名}の製品について説明するアシスタントです。
ナレッジベースをもとに、ユーザーの質問にはわかりやすく丁寧に答えてください。
できるだけ正確に説明し、必要なら手順も入れてください。
わからないことは無理に答えず、サポート窓口を案内してください。
悪くはないですが
- 「わかりやすく」の指示はあるが、具体的にどうすればいいかの記載がない
- 手順を入れる場面が「必要なら」で基準があいまい
- 「答えられない時の対応」は書いてあるが、やや感覚的でフォーマットとして弱い
などの改善点が見られます。
あなたは{会社名}の製品に関する専門家アシスタントです。ユーザーの質問に対して、以下のルールに従って回答してください。
1. 提供されたナレッジベースの情報のみを使用して回答してください
2. 回答は簡潔かつ正確に、専門用語を避けてわかりやすく説明してください
3. 製品の特徴や使い方について質問された場合は、具体的な手順や例を含めて説明してください
4. ナレッジベースに情報がない場合は、カスタマーサービスへの問い合わせを誘導してください
このようにルールが具体的であり、RAG(検索型)チャットボットに必要な「範囲の明確化」と「説明方針の統一」ができていることが大切です。
また、単に「回答ルール」を書くだけでなく、検索クエリ拡張(ユーザー質問の意図をくみ取って適切な検索ワードに変換すること) の視点も加えると、さらに質が上がります。
実践を重ねることでより良いプロンプトエンジニアリングの方法を学習することが、検索精度を向上させることに繋がります。
コンテキスト変数を活用する
Difyのコンテキスト変数機能を活用することで、より柔軟で高度なRAGシステムを構築できます。
ユーザーの属性(部署、役職、使用製品など)を変数として設定し、それに応じた回答を生成できます。
例えば、初心者ユーザーには「基本マニュアル」を、上級者には「詳細技術資料」を参照するといった使い分けができます。
Difyのアプリ設定画面で「変数」として定義し、プロンプト内で{変数名}の形式で参照できます。
変数を活用することで、ユーザーごとにパーソナライズされた応答を実現できるでしょう。
DifyでのRAG活用についてよくある質問
ここからは、Difyを使ったRAG実装でよく寄せられる質問とその回答をご紹介します。
これからRAGシステムを構築する方にとって、参考になるヒントが含まれています。
実装時に直面しがちな課題とその解決策を知ることで、スムーズな開発が可能になるでしょう。
DifyにおけるRAG活用まとめ
この記事では、Difyを使ったRAG(検索拡張生成)システムの構築方法を紹介しました。
RAGはAIチャットボットの回答品質を大幅に向上させる技術であり、Difyを使えばプログラミングなしで簡単に実装できることがわかりました。
ただし、実践的なRAGシステムの構築には、チャンクサイズの最適化や適切なプロンプト設計など、試行錯誤が必要な部分も多くあります。
本記事で紹介した基本的な知識をベースに、実際に手を動かしながら学んでいくことで、より高度なスキルが身につくでしょう。
ナレッジを活かした高品質なAIチャットボットの開発に、ぜひチャレンジしてみてください!





