
「Difyを触っているけど、イマイチLLMが使いこなせていない」
という方もいるのではないでしょうか?
Difyの開発でLLMはアプリケーションの重要な項目です。
LLMは、種類も多数あり設定によって幅広く応答のパターンを変えられます。
この記事では、LLMについて基礎的な知識から実装する方法まで詳しく解説します。

生成AI活用の教科書
生成AIの専門家として、1000人以上が参加するAIセミナーを100回以上開催した実績を持つ。国会議事堂衆議院会館や三井物産株式会社などの一流機関でのAIセミナー主催、生成AIタスクフォースへの参画、Shift AIでの講師活動など幅広く活躍。5000名を超える「人生逃げ切りサロン」のAI講座監修や、上場企業におけるAI顧問・システム開発・研修なども手がける。総フォロワー数32万人を誇るAI情報発信アカウントを運営し、過去には3つの事業のM&A経験を持つなど、AIと経営の両面で豊富な知識と経験を有している。

LLMの基礎知識を理解しよう!

LLMとはAIアプリケーションにおける言語処理を担う機能です。
まずは、LLMの基本的な概要を紹介します。
定義や学習方法について詳しく解説するので見ていきましょう。
LLMとは?定義と仕組み
LLMの定義や仕組みを簡単に説明します。
LLMとはLargeLanguageModelの略で、大規模言語モデルのことを指します。
LLMは、大量のWEBやテキストデータの知識から成り立っていてそれらの情報をもとに言語を処理します。
また、言語を処理する仕組みには、Transfornerアーキテクチャという技術が使われているのがポイントです。
Transformerアーキテクチャとは言語を並行して処理する仕組みのことです。
例えば、「これはりんごです。」という文章がある場合、文章を「これ」、「りんご」、「です」という単語に分割して、それらを同時に処理するのです。
この処理が採用されていることによって、高速で大規模な言語処理が可能となります。
LLMが学習を行う方法
LLMが知識となるデータを学習する方法は主に次の2通りです。
Pre-Training(事前学習)
文書やWEBサイトの情報などを読み込ませてデータベースとする方法です。
モデルによって言語の数も異なりますが、30~5000億語のデータが内蔵されます。
また、モデルによってこの学習によるデータを学習した年月も発表されています。
Fine-Tuning(ファインチューニング)
事前学習によるデータを用いて、問題解決のためにモデルを最適化する方法です。
少ないデータで効率的に調整ができるのが特徴です。
LLMはこれらの方法で学習を行い、言語処理に役立てていきます。
データの正確さや量はLLMの性能に大いに関係する項目です。
うまく利用しよう!LLMでできること

LLMの言語処理能力を利用してできることは多様です。
LLMの種類によっても違いはありますが、主な機能を4つご紹介します。
アプリケーション作成に活用できるLLMの機能は以下の通りです。
テキスト生成
LLMの機能のうち、代表的なものはテキスト生成です。
- インターネット上の記事
- メール
- プログラミングのコード
- 詩
- 企業の定款
など、あらゆる種類のテキストを自動で作成してくれます。
同じメールでも時候のありなしや、宛先に応じて文体を指定するなど、詳しく指示を出すことが可能です。
Difyのアプリケーションにおいては、LLMの働きにより自由度の高いテキスト生成ができます。
エージェントやチャットボットにおいてユーザーの指示通りに、人の能力以上の語彙と構成の機能を活用して高度な文章を生成します。
翻訳
LLMは、別の言語に翻訳する能力もあります。
翻訳と言っても、同じ文章を日本語に変換する結果は一通りではありません。
文章の意味を変えずに、用途に即して丁寧に返事をします。
アプリケーションにおいて、多言語をサポートする必要がある場合に活用できます。
他国のユーザーからの問い合わせを想定する際は、翻訳機能を役立てましょう。
要約
LLMの機能により、文章からの情報を収集して要約することができます。
長文にわたる資料や文書などを読み込ませると、簡潔にまとめて整理するので、ユーザーによる手入れの必要はありません。
Difyのナレッジベースには、大容量のWEBページやテキストなどを格納できます。
重要な事項をポイントを押さえて、見やすく出力するのが使いやすいポイントです。
質疑応答
DifyのAIアプリケーションは、ユーザーとのコミュニケーションが円滑にできます。
話し言葉による文章でも、気軽な口調で返答が可能です。
レスポンスも素早いので、スムーズに要件を聞いて解決するまで全てお任せできます。
顧客からの問い合わせやQ&Aに対応するコンテンツに応用できます。
DifyでLLMノードを使う方法を画像付きで解説!
DifyでLLMノードを利用して、ワークフローの編集をする方法です。
実際のDifyの編集画面の利用方法を画像付きで解説します。
新しいノードを追加してLLMを選択
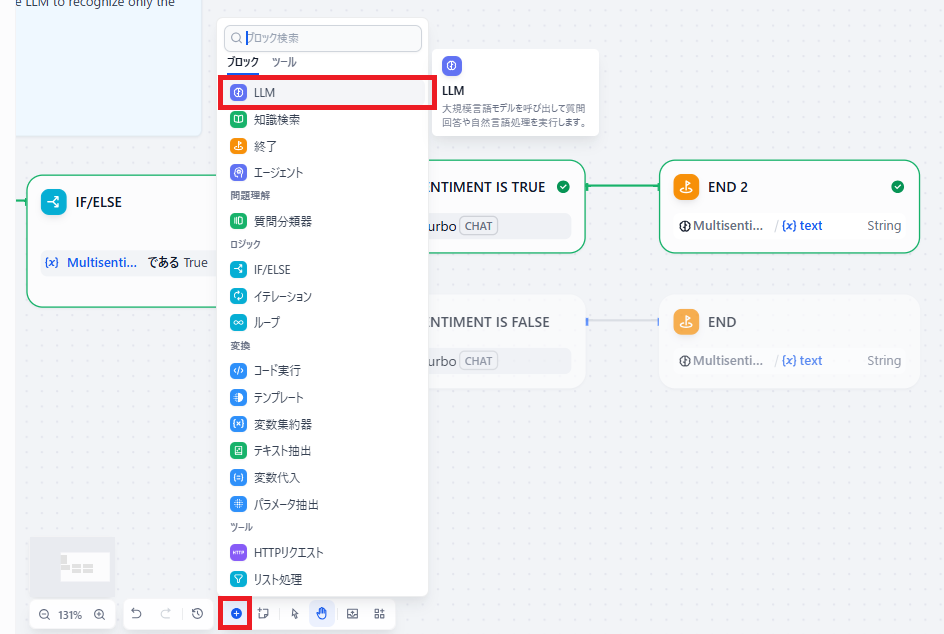
Difyのワークフローの編集画面です。
編集領域内の左下の「+」ボタンからノードを追加します。
青いアイコンのLLMを選択して、直前のノードに繋げます。
次はモデルを選択します。
モデルの選択
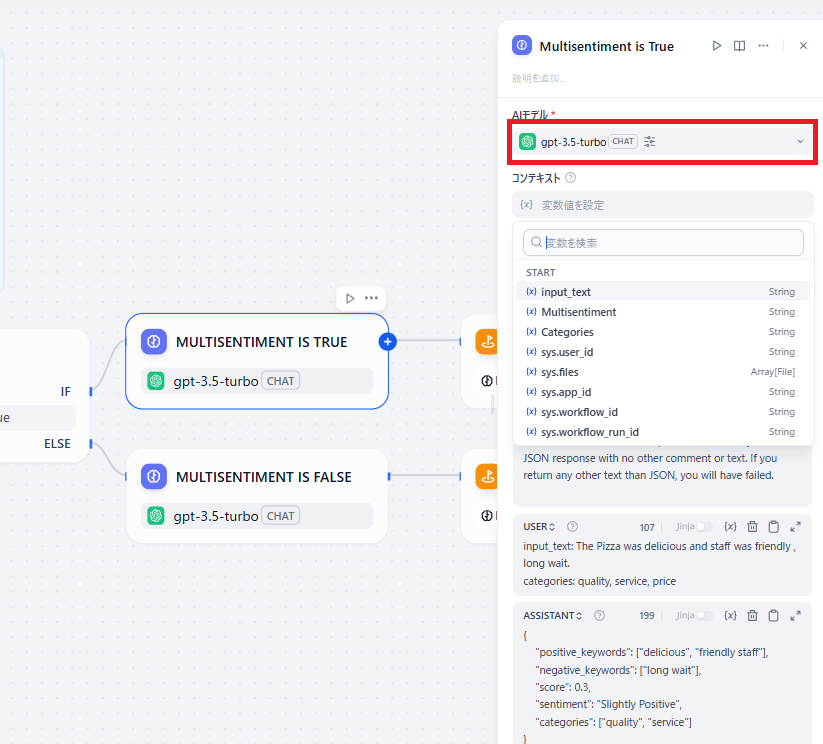
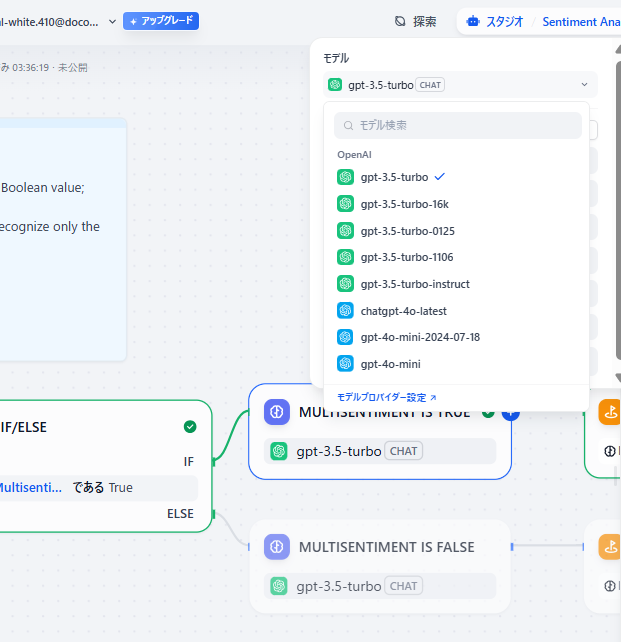
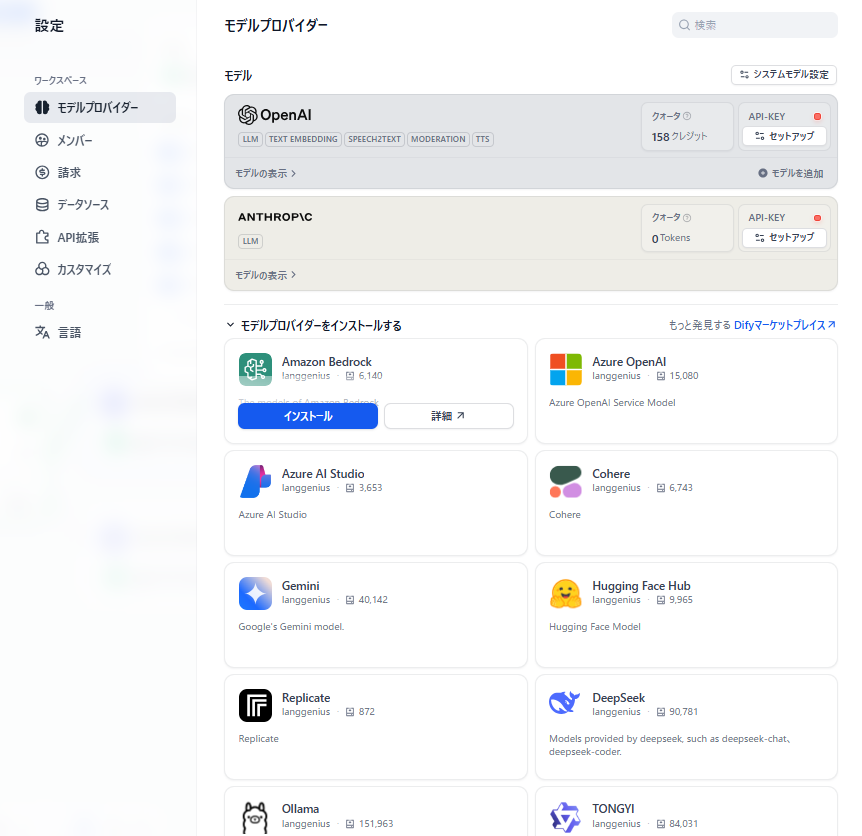
ボックスをクリックすると詳細設定の画面が開きます。
AIモデルのメニューから、モデル選択の画面に遷移します。
モデル一覧か、モデルプロバイダーの一覧から、用途に適したモデルを選びましょう。
モデルパラメータの設定
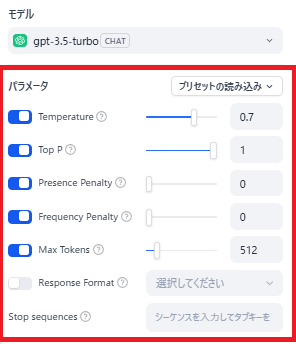
パラメータを設定します。
LLMモデルの右のボタンからLLMのパラメータ設定です。
TEMPARTURE
ランダム性
TOP K
結果の多様性
Presense Penalty
すでに出た結果にペナルティを課すことで繰り返しを防ぐ
Frequency Penalty
頻出する単語やフレーズにペナルティを課して混乱を防ぐ
MaxTokens
結果出力の最大文字数
Response Format
出力のフォーマット
StopSequens
出力を停止する最大の文章数
これらのパラメータの設定で、結果の継続性や検索の仕方が変動します。
初心者であればデフォルト設定のままをおすすめします。
使用の状況に応じて、「クリエイティブ」「バランス」「正確」という種類の値のセットを用いることも1つの選択肢です。
TEMPARTUREは0、MaxTokensは512となり処理時間と負荷が少ないです。
コンテキストの入力
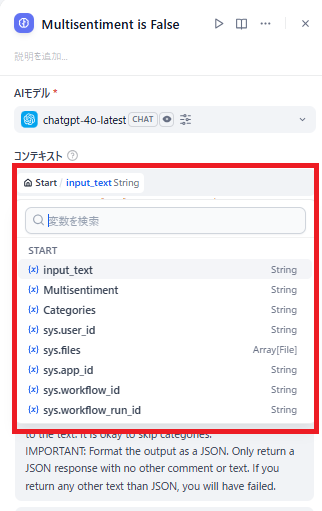
LLMのノードに、他ノードからのテキストなどの受け渡しとなるコンテキストを設定します。
必要な作業は、ノードの設定の画面でコンテキストの入力です。
コンテキストの入力欄をクリックすると、アプリケーション内で定義された変数一覧が開きます。
その中から選択すると、コンテキストの欄に変数が追加されます。
プロンプトの作成
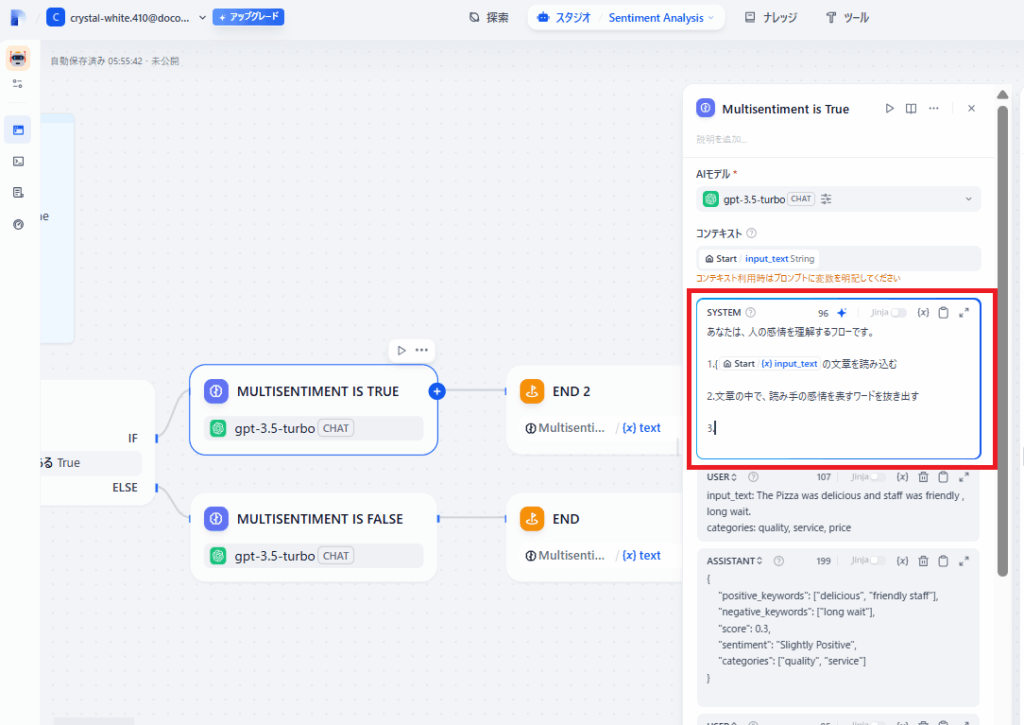
次は具体的に、LLMに対してプロンプトという指示を作成します。
箇条書きで、次のように記述します。
1.{{input_txt}}を読み込む
2.入力した文の中で感情を表すワードを抜き出す
3.それらが単一であるかを判断するコンテキストで選択した変数はプロンプトで利用する必要があります。
{{}}でくくってプロンプト内で利用します。
括弧をプロンプト内に記入すると変数の予測が出るので便利です。
プロンプトの記述によって、アプリケーションの精度や細かいニュアンスを聞く能力が高まります。
具体的にどういう観点で文章を処理、構成するかを丁寧に記述することがポイントです。
プロンプトの記述は慣れないうちは戸惑うことも多いので、AIによる生成を利用してもいいでしょう。
Difyで利用可能なLLM
Difyで利用可能なLLMのモデルについて解説します。
プロバイダーも有名企業の製品が多数あり、その中からあらゆるバージョンのモデルを選択可能です。
具体的な種類や利用方法を解説します。
サポートされるLLMプロバイダーとモデル
Difyでサポートされる主なLLMプロバイダーとモデルをあげます。
- OpenAI:GPT
- Google:Gemini
- Anthropic:Claude
Difyでサポートしていないモデルを追加する場合はAPIキーが必要です。
APIキーの取得は、プロバイダーのサイトにて行います。
Difyでは、その他多数のプロバイダーが利用可能です。
1つのプロバイダーごとに10個以上のモデルを使用することができ、無料プランでも高性能なモデルを利用できます。
後述しますが、同一アプリケーション内で違うモデルを利用するケースもあるので利便性が高いです。
Difyでのモデル選択と切り替え
Difyでのアプリケーション内では、自由にモデル選択、切り替えできます。
運用を開始してから、違うプロバイダーに変更することもできます。
また、1つのアプリケーション内で複数のプロバイダーを併用しても問題ありません。
処理ごとに使い分けることで、効率のいい動作が実現できます。
LLMのモデルはどうやって選べばいい?

LLMのモデルのラインナップは幅広く、それぞれ特徴が異なります。
LLMの選択基準を3つの観点から解説します。
性能で選ぶ
LLMの性能はそれぞれ異なり、得意な分野と苦手な分野があります。
LLMは既存の知識をもとに動作します。
前述した事前学習を行った日付が後になるほど、新しい知識を搭載しているので正確です。
また、複数の媒体を扱えるマルチモーダルや、入出力できるトークン数なども比較の要素となります。
コストで選ぶ
コスト面でもモデルによる違いがあります。
LLMの利用料金は、主に応答ごとの入出力に対して発生するもので、トークン数に応じて課金する形式です。
Difyのプランごとに、利用できるトークン数が定められていて、範囲外の利用については追加料金がかかります。
参考までに費用は100万トークンあたり入力は0.075〜15ドル、出力は0.6〜60ドル程度です。
応答速度で選ぶ
応答速度が高いLLMを採用すると、アプリケーションがスムーズに動作します。
チャットボットやエージェントではユーザーへのレスポンスが早いと、満足度が高まります。
応答速度は、アプリケーション作成において最重要となる課題です。
LLMによる応答速度は、テスト試行にて比較することをおすすめします。
DifyでLLMを連携させてAIアプリを作成しよう!
DifyでLLMを連携させてAIアプリを作成しましょう。
Difyはツールやナレッジなどの機能が充実しているので、上級者におすすめの連携パターンをご紹介します。
RAG(ナレッジ機能)によるLLMの補完
RAGを追加することで、LLMの機能が拡張されます。
Difyにおいては、ナレッジベースに相当するものでアプリケーションごとに追加可能です。
WEBサイトやファイルをそのまま読み込むことができ、キーワードや関連情報を元にLLMがそれらを参照して必要な情報を検索します。
企業の内部で扱う資料や文書などを、ナレッジベースに格納してアプリケーションにて利用する方法もあります。
RAGの追加は必須ではありませんが、独自性が高まるので活用することをおすすめします。
AIエージェントとLLM(推論・ツール連携)
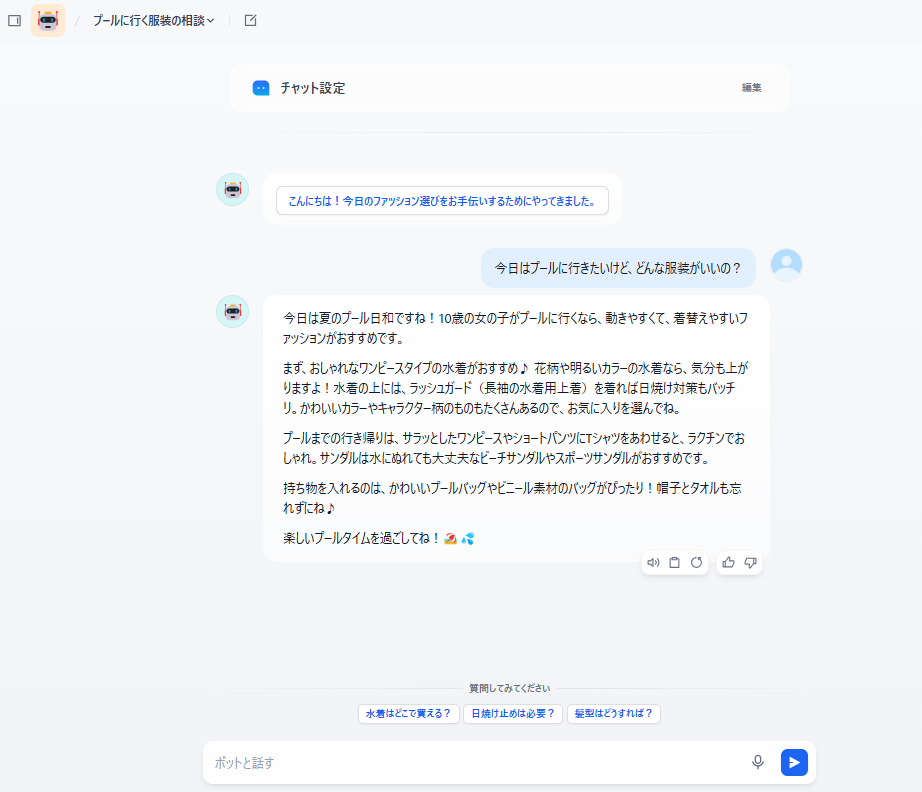
AIエージェントにおいて、LLMは総合的なタスクを遂行するのに役立ちます。
エージェントとは、漠然とした指示から応答を出力するアプリケーションのことです。
LLMは指示された文章を理解して、必要な情報を検索してユーザーの求める結果を構築します。
例えば「ユーザーの年齢、性別から最適なファッションを提案する」というあいまいなテーマでも実行可能です。
ワークフローと同じで、LLMへの指示をプロンプトにて記述していきます。
具体的な手順だけでなく、必要なツールや出力の形式なども細かく指定できて複雑な構成でも正常に動作します。
ワークフローにおけるLLMノードの連携
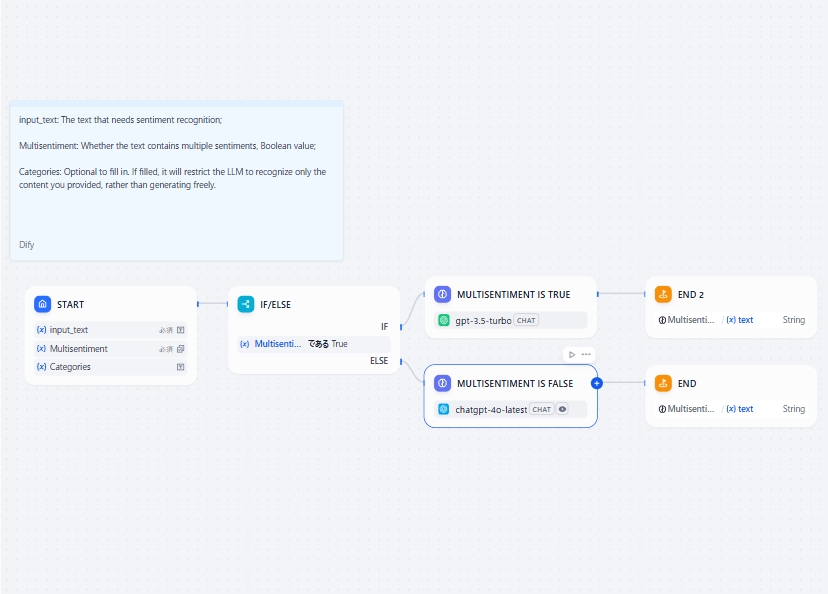
ワークフローにおいては、LLMノードを分岐処理や変数などと連携できます。
上の処理のように、IfElseの分岐処理においてそれぞれ違うLLMによる処理をすると効率的です。
DifyではLLMの機能を活用して、複雑なフローを構築することができるのが魅力です。
ワークフローの構成は全体像の設計が重要であり、細かい設定は大まかな構成の後に行います。
Difyでは、LLMの設定が初心者でも簡単なので安心です。
まとめ
AIアプリケーションにおいてのLLMの役割や仕組みについて記しました。
LLMは随時進化を続けていて高性能なモデルがたくさんリリースされています。
Difyでチャットボットやエージェントの開発を試してみたい方は、ぜひ以下の教材でDifyを詳しく学んでみてください。





